|
|
VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
简介
本项目基于PaddlePaddle框架复现了基于体素的3D目标检测算法VoxelNet,在KITTI据集上进行了实验。 项目提供预训练模型和AiStudio在线体验NoteBook。
背景
3D检测广泛用于自主导航、家政机器人以及AR/VR。LIDAR提供可靠的深度信息用于准确定位目标并表征其形状。
现有方法 - 将LIDAR投影到某个视角作为输入; - 采用3D体素,提取人工设计的体素特征; - 虽然有PointNet和Pointnet++这类点云学习网络,但还无法处理大规模点云数据。
这篇文章利用网络学习体素点特征,只使用点云实现了快速高效的3D目标检测。
算法解释
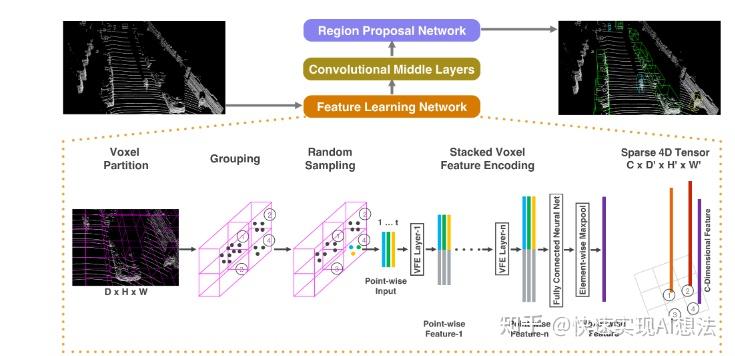
VoxelNet由三个功能块组成:特征学习网络、卷积中间层和区域候选网络。下面一一介绍: - 特征学习网络

首先将三维点云划分为一定数量的Voxel(就是将空间划分为一个一个栅格,用格子表示格子里的点云)并对这些voxel进行分组,再经过点的随机采样(每个格子的最大点云采样数量这里是T=35)以及归一化后,对每一个非空Voxel使用若干个VFE(Voxel Feature Encoding)层进行局部特征提取,得到Voxel-wise Feature。这里的VFE模型其实就是FC全连接模型。最后的输出形状为128×10×400×352.
为了聚合周围环境voxels的信息,使用3D卷积对4D tensor进行卷积,并进行reshape到3D tensor。每个卷积中间层顺序应用3D卷积、BN层和ReLU层。举例:输入尺寸(4D tensor)是128 × 10 × 400 × 352,输出尺寸(经过Convolutional Middle Layers之后)是64 × 2 × 400 × 352,然后reshape到 128 × 400 × 352变成3D tensor(注意到128 × 400 × 352正是BEV视图上的栅格尺寸)。

在提取到特征后,利用RPN模块预测候选检测框。如图所示,该网络包含三个全卷积层块(Block),每个块的第一层通过步长为2的卷积将特征图采样为一半,之后是三个步长为1的卷积层,每个卷积层都包含BN层和ReLU操作。将每一个块的输出都上采样到一个固定的尺寸并串联构造高分辨率的特征图。最后,该特征图通过两种二维卷积被输出到期望的学习目标:概率评分图(Probability Score Map)和回归图(Regression Map)
Probability Score Map的输出通道是2,分别对应positive和negative的分数,Regression map输出通道为14维,对于每个回归的Bounding box都用7维来表示,也就是中心位置 、候选框的长宽高和航向角,另外两个旋转轴默认为0,原因是地面水平。同理,假设预测的anchor用小标a表示,因此可定义如下的残差:
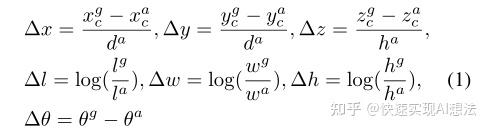
其中,是anchor框底部的对角线长度,采用的目的是用对角线齐次归一化和。然后定义可以最终的损失函数:
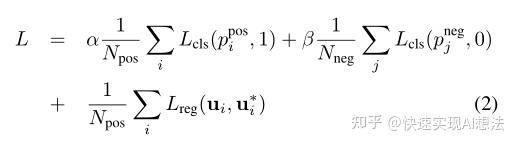
损失函数前面两项是正则化分类损失,其中和分别表示softmax层对正锚和负锚的分数,采用的是交叉熵表示,和为正定平衡系数。最后一项是回归损失,和是正锚的回归输出和ground truth,采用的是Smooth L1损失。
详细的参数设定需要查看论文才能更好理解~
论文: - [1] Yin Zhou, Oncel Tuzel. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
博客参考:
- VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
- 【3D目标检测】VoxelNet:End-to-End Learning for Point Cloud Based 3D Object Detection解读
项目参考: - https://github.com/qianguih/voxelnet
github repo实现精度 easy: 53.43 moderate:48.78 hard:48.06
- https://github.com/traveller59/second.pytorch
由于该论文并未提供开源的代码,目前也找不到能够复现其论文中指标的项目。 因此本项目根据参考项目(voxelnet-tensorflow)和该论文后续的算法改进版本(second)进行了复现。
复现精度
指标解释:>机器学习算法评估指标——3D目标检测
评价3D目标检测结果的指标主要是3D AP 和Bev AP。其含义是当预测框与真值框的交并比(IOU)大于一定阈值时,认为预测框正确的数量与所有真值框的比例。
IOU即两个框的相交范围与并集范围的比例。
在KITTI val数据集(50/50 split as paper)的测试效果如下表。
Car AP@0.70, 0.70, 0.70:
bbox AP:90.26, 86.24, 79.26
bev AP:89.92, 86.04, 79.14
3d AP:77.00, 66.40, 63.24
aos AP:38.34, 37.30, 33.19
Car AP@0.70, 0.50, 0.50:
bbox AP:90.26, 86.24, 79.26
bev AP:90.80, 89.84, 88.88
3d AP:90.75, 89.32, 87.84
aos AP:38.34, 37.30, 33.19
Car coco AP@0.50:0.05:0.95:
bbox AP:67.72, 63.70, 61.10
bev AP:67.13, 63.44, 61.15
3d AP:53.45, 48.92, 46.34
aos AP:28.82, 27.54, 25.55预训练权重和日志:百度网盘 | AiStudio存储
2、当将分类损失改为FocalLoss以及加入针对aos的direction分类损失时(后续实验表明direction损失只对aos起作用,可不用)
Car AP@0.70, 0.70, 0.70:
bbox AP:90.19, 85.78, 79.38
bev AP:89.79, 85.26, 78.93
3d AP:81.78, 66.88, 63.51
aos AP:89.81, 84.55, 77.71
Car AP@0.70, 0.50, 0.50:
bbox AP:90.19, 85.78, 79.38
bev AP:96.51, 89.53, 88.59
3d AP:90.65, 89.08, 87.52
aos AP:89.81, 84.55, 77.71
Car coco AP@0.50:0.05:0.95:
bbox AP:67.15, 63.05, 60.58
bev AP:68.90, 63.78, 61.08
3d AP:54.88, 49.42, 46.82
aos AP:66.89, 62.19, 59.23预训练权重和训练日志:百度网盘 | AiStudio存储
- 另外,论文中没提及的细节,本项目均参考Second项目的实施。
- 仓库内的log文件夹下存放有两个训练日志和可视化曲线日志。
开始
数据集解压
约15分钟.
%cd /home/aistudio/
!rm -rf kitti/
!mkdir -p kitti/training/velodyne_reduced
!mkdir -p kitti/testing/velodyne_reduced
!unzip data/data50186/data_object_calib.zip -d kitti/
!unzip data/data50186/image_training.zip -d kitti/training/
!unzip data/data50186/data_object_label_2.zip -d kitti/training/
!unzip data/data50186/velodyne_training_1.zip -d kitti/training/
!unzip data/data50186/velodyne_training_2.zip -d kitti//training/
!unzip data/data50186/velodyne_training_3.zip -d kitti/training/
!unzip data/data50186/image_testing.zip -d kitti/testing/
!unzip data/data50186/velodyne_testing_1.zip -d kitti/testing/
!unzip data/data50186/velodyne_testing_2.zip -d kitti/testing/
!unzip data/data50186/velodyne_testing_3.zip -d kitti/testing/
!mv kitti/training/training/* kitti/training/
!rm -rf kitti/training/training/
!mv kitti/testing/testing/* kitti/testing/
!rm -rf kitti/testing/testing/
!mkdir kitti/training/velodyne
!mv kitti/training/velodyne_training_1/* kitti/training/velodyne/
!mv kitti/training/velodyne_training_2/* kitti/training/velodyne/
!mv kitti/training/velodyne_training_3/* kitti/training/velodyne/
!rm -rf kitti/training/velodyne_training_1
!rm -rf kitti/training/velodyne_training_2
!rm -rf kitti/training/velodyne_training_3
!mkdir kitti/testing/velodyne
!mv kitti/testing/velodyne_testing_1/* kitti/testing/velodyne
!mv kitti/testing/velodyne_testing_2/* kitti/testing/velodyne
!mv kitti/testing/velodyne_testing_3/* kitti/testing/velodyne
!rm -rf kitti/testing/velodyne_testing_1
!rm -rf kitti/testing/velodyne_testing_2
!rm -rf kitti/testing/velodyne_testing_3
!mv kitti data/至此,数据集的结构:
└── KITTI_DATASET_ROOT
├── training <-- 7481 train data
| ├── image_2 <-- for visualization
| ├── calib
| ├── label_2
| ├── velodyne
| └── velodyne_reduced <-- empty directory
└── testing <-- 7580 test data
├── image_2 <-- for visualization
├── calib
├── velodyne
└── velodyne_reduced <-- empty directory3,712 data samples fortraining and 3,769 data samples for validation
安装依赖
最适合的环境配置: - python版本:3.7.4 - PaddlePaddle框架版本:2.2.1 - CUDA 版本: NVIDIA-SMI 450.51.06 Driver Version: 450.51.06 CUDA Version: 11.0 cuDNN:7.6
注意: 由于PaddlePaddle/cuDNN本身的BUG,CUDA 10.1版本当batch size > 2时会报如下错误:
OSError: (External) CUDNN error(7), CUDNN_STATUS_MAPPING_ERROR.
[Hint: &#39;CUDNN_STATUS_MAPPING_ERROR&#39;. An access to GPU memory space failed, which is usually caused by a failure to bind a texture. To correct, prior to the function call, unbind any previously bound textures. Otherwise, this may indicate an internal error/bug in the library. ] (at /paddle/paddle/fluid/operators/conv_cudnn_op.cu:758)因此单卡如果环境不是CUDA 11.0以上,config文件中batch size设置为2即可,后续通过训练的accum_step参数开启梯度累加起到增大bs的效果。设置accum_step=8即表示bs=16,并做相应config文件的初始学习率调整。
!pip install distro shapely pybind11 pillow fire memory_profiler psutil scikit-image==0.14.2
!pip install numpy==1.17.0
!pip install numba==0.48.0(由于Notebook不支持导入当前整个项目到Python环境,以下操作在终端命令行执行)
准备部分
1. 为numba设置cuda环境
export NUMBAPRO_CUDA_DRIVER=/usr/lib/x86_64-linux-gnu/libcuda.so
export NUMBAPRO_NVVM=/usr/local/cuda/nvvm/lib64/libnvvm.so
export NUMBAPRO_LIBDEVICE=/usr/local/cuda/nvvm/libdevice2. 将当前项目加到环境中
export PYTHONPATH=$PYTHONPATH:/home/aistudio/VoxelNet3. 数据预处理
从label中分类别抽取真值信息以及对点云进行降采样。(约7分钟)
cd /home/aistudio/VoxelNet/voxelnet/
python create_data.py create_kitti_info_file --data_path=/home/aistudio/data/kitti # Create kitti infos
python create_data.py create_reduced_point_cloud --data_path=/home/aistudio/data/kitti # Create kitti reduced point
python create_data.py create_groundtruth_database --data_path=/home/aistudio/data/kitti # Create kitti gt打印信息如下:
Generate info. this may take several minutes.
Kitti info train file is saved to /home/aistudio/data/kitti/kitti_infos_train.pkl
Kitti info val file is saved to /home/aistudio/data/kitti/kitti_infos_val.pkl
Kitti info trainval file is saved to /home/aistudio/data/kitti/kitti_infos_trainval.pkl
Kitti info test file is saved to /home/aistudio/data/kitti/kitti_infos_test.pkl
[100.0%][===================>][40.86it/s][01:44>00:00]
[100.0%][===================>][35.31it/s][01:47>00:00]
[100.0%][===================>][39.13it/s][03:49>00:00]
[100.0%][===================>][28.71it/s][01:53>00:00]
load 14357 Car database infos
load 2207 Pedestrian database infos
load 734 Cyclist database infos
load 1297 Van database infos
load 56 Person_sitting database infos
load 488 Truck database infos
load 224 Tram database infos
load 337 Misc database infos4. 修改配置文件
voxelnet/configs/car.configs
train_input_reader: {
...
database_sampler {
database_info_path: &#34;/home/aistudio/data/kitti/kitti_dbinfos_train.pkl&#34;
...
}
kitti_info_path: &#34;/home/aistudio/data/kitti/kitti_infos_train.pkl&#34;
kitti_root_path: &#34;/home/aistudio/data/kitti&#34;
}
...
eval_input_reader: {
...
kitti_info_path: &#34;/home/aistudio/data/kitti/kitti_infos_val.pkl&#34;
kitti_root_path: &#34;/home/aistudio/data/kitti&#34;
}设置注意事项:
1、若训练要开启梯度累加选项,则: - 学习率的decay_steps按照梯度累加后的batch size对应的总steps来设置。 - train_config.steps则按未梯度累加时对应的初始batch size对应的总steps来设置
2、 配置文件需放置于voxelnet/configs/***.py
快速开始
1. 训练
训练一个epoch, V100 16G大约15分钟。显存占用11G左右。
python ./pypaddle/train.py train --config_path=./configs/config.py --model_dir=./output2. 评估
V100 16G 大约5分钟
python ./pypaddle/train.py evaluate --config_path=./configs/config.py --model_dir=./output --ckpt_path=./output/voxelnet-278400.ckpt3. 可视化预测
3D可视化需要GUI,Notebook环境不支持动态GUI调用显示。需在本地测试。 详细查看README.md。
4. 一个简单的BEV视角可视化例子
为了方便查看预测结果,下面的cell提供了一个在notebook中查看二维bev视角的可视化例子,可以在notebook执行。 由于只保留了相机视角范围内的结果(Points that are projectedoutside of image boundaries are removed(in Paper Section 3.1)),所以车身后面没有检测框。
%cd /home/aistudio/VoxelNet/
!export PYTHONPATH=$PYTHONPATH:/home/aistudio/VoxelNet
import paddle
import numpy as np
import matplotlib.pyplot as plt
import pickle
from pathlib import Path
import voxelnet.pypaddle.builder.voxelnet_builder as voxelnet_builder
import voxelnet.builder.voxel_builder as voxel_builder
import voxelnet.builder.target_assigner_builder as target_assigner_builder
import voxelnet.pypaddle.builder.box_coder_builder as box_coder_builder
from voxelnet.data.preprocess import merge_voxelnet_batch
from voxelnet.configs import cfg_from_config_py_file
from voxelnet.utils import vis
def example_convert_to_paddle(example, dtype=paddle.float32,
) -> dict:
example_paddle = {}
float_names = [
&#34;voxels&#34;, &#34;anchors&#34;, &#34;reg_targets&#34;, &#34;reg_weights&#34;, &#34;bev_map&#34;, &#34;rect&#34;,
&#34;Trv2c&#34;, &#34;P2&#34;
]
for k, v in example.items():
if k in float_names:
example_paddle[k] = paddle.to_tensor(v, dtype=dtype)
elif k in [&#34;coordinates&#34;, &#34;labels&#34;, &#34;num_points&#34;]:
example_paddle[k] = paddle.to_tensor(
v, dtype=paddle.int32)
elif k in [&#34;anchors_mask&#34;]:
example_paddle[k] = paddle.to_tensor(
v, dtype=paddle.uint8)
else:
example_paddle[k] = v
return example_paddle
paddle.set_device(&#39;gpu&#39;) # 设置cpu/gpu
config_path = &#34;home/aistudio/VoxelNet/voxelnet/configs/config.py&#34;
config = cfg_from_config_py_file(config_path)
input_cfg = config.eval_input_reader
model_cfg = config.model.voxelnet
ckpt_path = &#34;/home/aistudio/VoxelNet/voxelnet/output/voxelnet-278400.ckpt&#34;
model_cfg.voxel_generator.point_cloud_range = [0, -40, -3, 70.4, 40, 1]
voxel_generator = voxel_builder.build(model_cfg.voxel_generator)
######################
# BUILD TARGET ASSIGNER
######################
bv_range = voxel_generator.point_cloud_range[[0, 1, 3, 4]]
box_coder = box_coder_builder.build(model_cfg.box_coder)
target_assigner_cfg = model_cfg.target_assigner
target_assigner = target_assigner_builder.build(target_assigner_cfg,
bv_range, box_coder)
net = voxelnet_builder.build(model_cfg, voxel_generator, target_assigner)
net.eval()
state = paddle.load(ckpt_path)
net.set_state_dict(state)
out_size_factor = model_cfg.rpn.layer_strides[0] // model_cfg.rpn.upsample_strides[0]
grid_size = voxel_generator.grid_size
feature_map_size = grid_size[:2] // out_size_factor
feature_map_size = [*feature_map_size, 1][::-1]
anchors = target_assigner.generate_anchors(feature_map_size)[&#34;anchors&#34;]
anchors = anchors.reshape((1, -1, 7))
info_path = input_cfg.kitti_info_path
root_path = Path(input_cfg.kitti_root_path)
with open(info_path, &#39;rb&#39;) as f:
infos = pickle.load(f)
info = infos[564] # 测试目标点云
# print(info)
v_path = info[&#39;velodyne_path&#39;]
v_path = str(root_path / v_path)
points = np.fromfile(
v_path, dtype=np.float32, count=-1).reshape([-1, 4])
voxels, coords, num_points = voxel_generator.generate(points, max_voxels=40000)
print(voxels.shape)
# add batch idx to coords
# coords = np.pad(coords, ((0, 0), (1, 0)), mode=&#39;constant&#39;, constant_values=0)
image_idx = info[&#39;image_idx&#39;]
rect = info[&#39;calib/R0_rect&#39;].astype(np.float32)
Trv2c = info[&#39;calib/Tr_velo_to_cam&#39;].astype(np.float32)
P2 = info[&#39;calib/P2&#39;].astype(np.float32)
example = {
&#34;anchors&#34;: anchors,
&#34;voxels&#34;: voxels,
&#34;num_points&#34;: num_points,
&#34;num_voxels&#34;: np.array([voxels.shape[0]], dtype=np.int64),
&#34;coordinates&#34;: coords,
&#34;rect&#34;: rect,
&#34;P2&#34;: P2,
&#34;Trv2c&#34;:Trv2c,
&#39;image_idx&#39;: image_idx
}
batch_example = [example]
examples = merge_voxelnet_batch(batch_example)
examples = example_convert_to_paddle(examples)
with paddle.no_grad():
pred = net(examples)[0]
boxes_lidar = pred[&#34;box3d_lidar&#34;].detach().cpu().numpy()
vis_voxel_size = [0.1, 0.1, 0.1]
vis_point_range = [-50, -30, -3, 50, 30, 1]
bev_map = vis.point_to_vis_bev(points, vis_voxel_size, vis_point_range)
bev_map = vis.draw_box_in_bev(bev_map, vis_point_range, boxes_lidar, [0, 255, 0], 2)
# plt.savefig(&#39;/home/aistudio/val564.png&#39;)
plt.imshow(bev_map)
paddle.device.cuda.empty_cache()
/home/aistudio/VoxelNet
cfg_file must be located in ./configs/***.py...
load config from home/aistudio/VoxelNet/voxelnet/configs/config.py...
(13282, 35, 4)
结语
复现心得:
这篇论文在第四届论文复现赛的时候我就进行了复现,并未成功,相差甚远。由于论文没有开源代码,网络上也没有达到论文精度的项目,很难从头开始自己全部重写。于是我换了一个思路,既然这篇论文是非常经典的论文,后续肯定有人基于这个思路进行改进。果然找到了second。second这篇论文几乎重现了voxelnet的所有方法(但据作者说并没有完全复现原始的voxelnet),不过加入了稀疏卷积使得速度和精度得到了巨大提升。于是我的思路就变成了从second中去掉它改进的部分内容,使其复原原始的voxelnet,来减少自己重写代码的工作量。
由于之前第四届比赛时的经验,这次遇到的问题都不多,或者说当时已经遇到了,直接拿我当时的代码进行替换,一个函数一个函数输入输出对齐测试即可。并且只需要对照X2Paddle进行对齐即可。
第四届和这一次遇到的主要问题都是内存泄漏问题。不过这一次,找到了问题所在。
1.这里总结一下几个常犯的内存泄漏错误原因。
- loss在用于取值打印或者用于其他计算时,没有.detach()或者.numpy()
- 如果model本身内部要存一些每一次前向计算后的指标,指标一定也要在前向计算后detach再赋值到model内的变量(这是我找了超级久的泄漏问题)。
2.enisum函数。这个函数虽然paddle2.2提供了,但是还有bug。用的时候报错了。
我在paddlenlp(https://github.com/PaddlePaddle/PaddleNLP/blob/develop/paddlenlp/ops/einsum.py) 中找到了可以正常使用的版本。
3.mask赋值。问题如下: 写了一个mask(bool类型)的赋值函数:
def mask_slice_v1(data, mask):
&#34;&#34;&#34;
问题:
data.shape = [x,y], type: float...
mask.shape = [x] ,type: bool
in torch, can do it by data[mask] to get shape:[x,y] result.
但是padlde目前还不行。
&#34;&#34;&#34;
data_shape = data.shape
mask = mask.unsqueeze(-1) # [x,1]
mask = paddle.tile(mask,[1,data_shape[1]]) # [x,y]
slice = paddle.masked_select(data,mask) # [x*y]
return slice.reshape([-1,data_shape[1]]) # [x,y]

引用
- Thanks for yan yan&#39;s second.pytorch project.
@inproceedings{Yin2018voxelnet,
author={Yin Zhou, Oncel Tuzel},
title={VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2018}
} |
|



 发表于 2023-1-16 17:18:35
发表于 2023-1-16 17:18:35